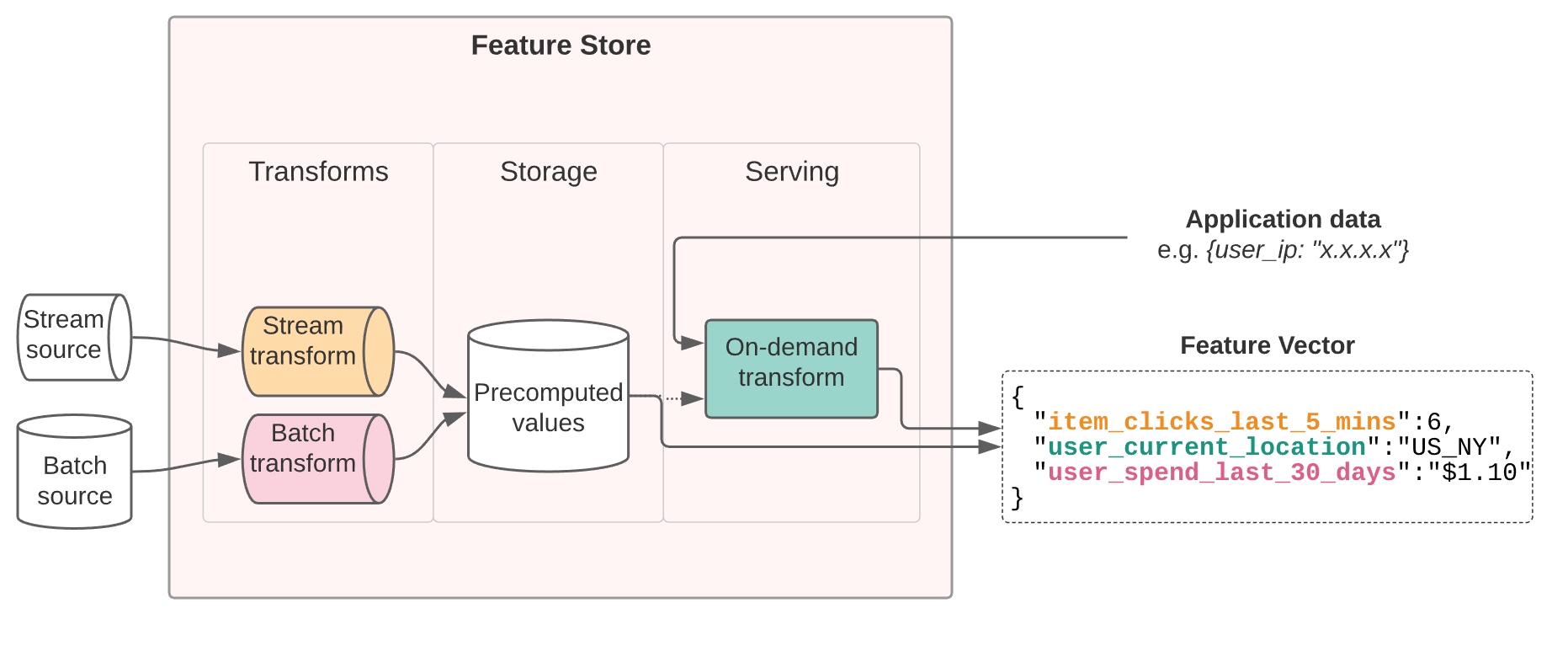
Recently MLOps scientists have come forward to recognize the true potential of a feature store in the higher significance category with MLOps software. Unrelated to their recent rise in popularity – the feature stores were in use even before the name feature store was coined. Tech giants, including UBER, Airbnb, and Twitter, simultaneously constructed their primeval feature store mechanisms. This led to the arrival of 3 distinct and different feature store architectures, namely:
Literal
Virtual
Physical
Feature Store – An Overview
In this post, we will discuss in detail – why there was a need for feature stores to begin with. Also, we shall discuss the prime goals of MLOps that, in terms, became the motivation for feature store architecture.
Feature Store Goals
Before going into the feature stores, we must define their goals and motivations first.
MLOps comes with four major goals:
Reduction in Iteration Time of a model
Enhanced Model Reliability
Compliance
Improvement in Collaboration
Where does the feature store come in this?
As an integral part of the MLOps stack, the feature store aids an organization in achieving the goals mentioned above. Moreover, feature stores work to enhance transformation cycles and data analysis of the ML processes.
Let’s discuss these 4 goals;
Decrease in Iteration Time
The iteration cycle constitutes numerous experimentation loops through some deployment tools occasionally.
ML is an iterative process – with models as black boxes. Thus, the enhancements over them are opaque and non-linear. To improve the performance of a model, data scientists pull out the functional insights from feature engineering (one of the main data sources) and present those as the distinct features of the models.
In ML use cases, particularly the text and tabular data, scientists spend a massive chunk of time fine-tuning the features. The faster the features iteration, the faster scientists will be able to improve the models.
Consequently, there are 2 prime iteration cycles;
Deployment
Experimentation
*Multi-experimentation cycles are needed per deployment; thus, feature stores optimize both of these.
Experimentation Process
Feature stories must aspire to the organization of experimentation cycles, and while in the experimentation phase, data scientists might get to the point of creating notebooks in dozens for the eventual creation of hundreds of varying data sets.
The next step is an organization of the datasets between the notebooks – ad-hoc, while the documentation often remains sparse. The feature store essentially enforces standardized manners for naming, documenting, and creating the features.
For decreased iteration time, the Next step is:
Deployment
The feature store lets data scientists deploy feature logic to production. Instead of writing the experimentation logic again, they can easily deploy it as it is. This not only removes the would-be human error but also saves time. The feature stores also offer more essential functionality, including;
Version control
Data Monitoring
Access Control
The second goal of MLOps and feature store is:
Increase Model Reliability
Features stores are known to limit possible errors to boost reliability. Data scientists have to have command over DevOps and DataOps while also being experts with data. This way, many things could go possible wrong if these conditions are not met, which is likely the case with most ML teams. This is where the feature stores abstract DevOps and DataOps in a manner that fits the ML process. This is done by removing the data engineering overhead required for the data scientists to perform their jobs.
Compliance
Not every model needs to access all features. Most of the ML use cases work with sensitive data, which preserves compliance and becomes important. Some of the data is regulated across organizations, while other data types are used freely. Sometimes the same data present with an altered context changing compliance rules. Also, sometimes the same data used in varying models will also be subject to varying rules, like a model used for add optimization can and will probably use more data than a model used for processing house loan applications. The data scientists can integrate the rules into a feature store to ensure that governance is locked tight.
Improve Collaboration
In feature stores, across the team, sharing and communication are promoted. Without these siloed notebooks and transformations, features are mostly copied and pasted. The feature stores here ensure that the transformations get defined in standardized forms. This way, data scientists can share and comprehend each other’s work easily while also discovering and leveraging the work together or in teams.
Final Word
Feature store mechanism is the grace saver for MLOps projects.
Not only do feature stores standardize the entire process, but the feature lineage also enables data scientists to understand the steps needed to create each feature. In a feature store, the resources can be reused without risking the change in upstream logic by making the feature logic and transformations immutable. This essentially lets data scientists safely use data from different teams.